

摘要
本文将会为读者展示如何使用卷积神经网络(Convolutional Neural Network,CNN)和决策树如何相互配合,掌握在人类世界难以解决的围棋游戏策略问题。由于整个搜索空间巨大,评估棋盘也是一个相当困难的问题,因此围棋游戏被人类视为经典游戏中最具有挑战性的游戏之一,而卷积神经网络是一种深度学习模型,具有优秀的图像处理和特征提取能力,适合应用于围棋中。故在此我们将介绍一种新的方法,使用“策略网络”和“决策树”来进行解空间的构建与搜索,并且达到人类棋手世界的一定水平。
关键词:卷积神经网络; 围棋智能;
1 策略网络
1.1 原理
策略网络(PolicyModel)是一种基于深度学习的模型,用于根据当前的围棋局势预测下一步的最佳落子位置。策略网络的核心思想是通过训练模型来学习围棋局势中的关键特征,并根据这些特征进行决策。其中,CNN作为策略网络的核心组件,在围棋中具有良好的效果。
策略网络包含了多个卷积层,在围棋局势中通过滑动窗口的方式提取特征。卷积层的参数包括输入通道数、输出通道数和卷积核的大小等。特征图的维度在经过每个卷积层后逐渐减小。在LetGo模型中将会默认输入19×19的棋盘矩阵,输出一个19×19的策略概率矩阵。
卷积层的作用是对输入局势进行卷积运算,提取局势中的空间特征。卷积核的选择和滑动窗口的方式都会影响特征提取的效果。全连接层则用于将卷积层的输出映射为一维向量,用于后续的位置概率计算。
在策略网络中,激活函数的选择对模型的性能有着重要的影响。常用的激活函数包括ReLU、Sigmoid和Tanh等。在代码中,策略网络使用了ReLU作为激活函数,它具有较好的非线性特性,能够更好地捕捉到围棋局势中的信息。
1.2 结构
策略网络整体由4个卷积层和1个全连接层构成,前面4个卷积层的通道数分别为:2、40、64、128、4。网络的最后一层全连接层将4×19×19的数据变为19×19的策略概率矩阵,概率最高的位置即为策略网络学习到的最优落子点。概率数据可以直接根据落子检查从最高概率向下挑选,也可作为剪枝策略为决策树进行预剪枝操作。
1.3 训练
1.3.1 训练数据
数据来源于各大围棋网站的sgf棋谱文件,这个文件可以将每场棋局的每一步都记录下来,LetGo将会把每一步还原成一张张棋盘矩阵,描述当前对局,并且每一张棋盘矩阵会被进行反转、旋转等操作,目的在于让CNN接收到各种形状的棋形,利于模型做出判断。
输入网络的数据为2通道,19×19的棋盘矩阵,其中第一个通道为棋盘上的落子情况,1代表黑子,-1代表白子。第二个通道为当前棋盘可以落子的区域,1代表可以落子,0代表禁着。这个设计十分有利于模型在近战的能力增强,在此之前只有一个通道的模型在近战的时候通常会处于劣势,且不愿与玩家在同一地点过多交战,加入此通道后LetGo在近战的能力和耐力明显增加。
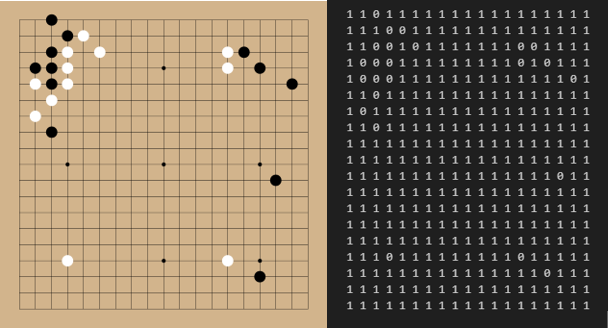
1.3.2 训练步骤
设置batch size为64,将所有棋盘数据随机打乱,最后将其放入模型中进行训练,经过30轮训练后策略模型收敛。
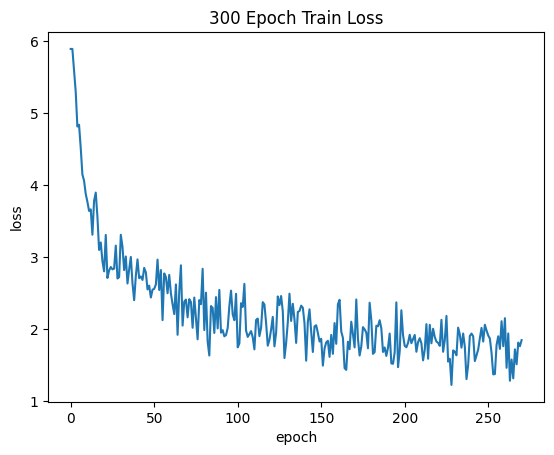
总结与展望
目前本文基本介绍了基于CNN的策略网络的构建方式,后面还会更新决策树相关的内容,想要体验LetGo可通过本站提供的平台与其对弈。
点此体验LetGo
参考文献
[1] 陶九阳,吴琳,胡晓峰. AlphaGo技术原理分析及人工智能军事应用展望[J]. 指挥与控制学报, 2016, 2 (02): 114-120.
[2] 邱国栋,任博. 机器学习与行动者能力:技术可供性视角——以谷歌AlphaGo为案例[J]. 科技进步与对策, 2023, 40 (14): 1-11.
[3] 阮晓东. 从AlphaGo的胜利看人工智能的未来[J]. 新经济导刊, 2016, (06): 69-74.
[4] 章胜, 龙强, 孔轶男, 王宇. 围棋人工智能AlphaGo系列算法的原理与方法[J]. 科技导报, 2023, 41 (07): 79-97.
[5] 陈东焰, 陆畅. 从AlphaGo看机器学习[J]. 科技创新导报, 2020, 17 (13): 146+148.
[6] 陈铭禹. AlphaGo与AlphaZero原理和未来应用研究[J]. 通讯世界, 2019, 26 (12): 22-23.
[7] 郑炳楠, 贺威. 先天综合判断观照下的深度增强学习:以AlphaGo Zero为例[J]. 南京林业大学学报(人文社会科学版), 2019, 19 (01): 60-68.
[8] 赵奥佩. 从AlphaGo看神经认知的逻辑[D].贵州大学,2019.
[9] Silver, D., Schrittwieser, J., Simonyan, K. et al. Mastering the game of Go without human knowledge. Nature 550, 354–359 (2017).
[10] Silver, D., Huang, A., Maddison, C. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016).
[11] Schrittwieser, J., Antonoglou, I., Hubert, T. et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 588, 604–609 (2020).