843 字
4 分钟
LetGo

策略网络
简介
策略网络整体由4个卷积层和1个全连接层构成,前面4个卷积层的通道数分别为:2、40、64、128、4。网络的最后一层全连接层将4×19×19的数据变为19×19的策略概率矩阵,概率最高的位置即为策略网络学习到的最优落子点。概率数据可以直接根据落子检查从最高概率向下挑选,也可作为剪枝策略为决策树进行预剪枝操作。
策略网络源码
PolicyModel.py
from torch import nn
import torch.nn.functional as F
# 策略模型
class PolicyModel(nn.Module):
'''
19x19 棋盘矩阵 --> 卷积层 x 3 --> 全连接层 x 1 --> 19x19 概率矩阵 (log_softmax)
Inputs: [batch_size, channel=2, width, width]
Output: [batch_size, width, width]
'''
def __init__(self, width=19) -> None:
super().__init__()
self.board_width = width
self.conv1 = nn.Conv2d(2, 40, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(40, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(128, 4, kernel_size=1)
self.policy_fc1 = nn.Linear(4*width*width, width*width)
def forward(self, state_input):
x = F.relu(self.conv1(state_input))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = x.view(-1, 4*self.board_width*self.board_width)
x = self.policy_fc1(x)
x = F.log_softmax(x)
return x网络训练
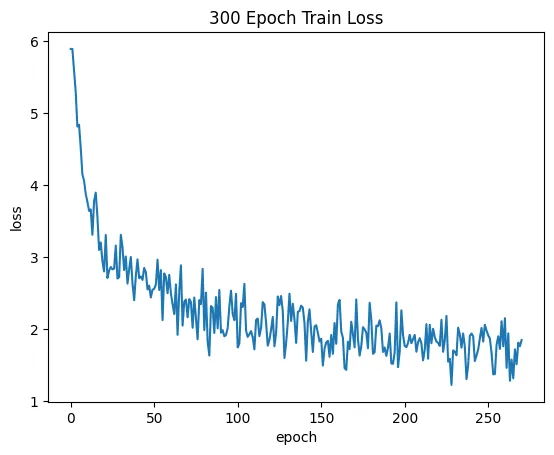
数据来源于各大围棋网站的sgf棋谱文件,这个文件可以将每场棋局的每一步都记录下来,LetGo将会把每一步还原成一张张棋盘矩阵,描述当前对局,并且每一张棋盘矩阵会被进行反转、旋转等操作,目的在于让CNN接收到各种形状的棋形,利于模型做出判断。
输入网络的数据为2通道,19×19的棋盘矩阵,其中第一个通道为棋盘上的落子情况,1代表黑子,-1代表白子。第二个通道为当前棋盘可以落子的区域,1代表可以落子,0代表禁着。这个设计十分有利于模型在近战的能力增强,在此之前只有一个通道的模型在近战的时候通常会处于劣势,且不愿与玩家在同一地点过多交战,加入此通道后LetGo在近战的能力和耐力明显增加。
下图为该程序使用matplotlib绘制的棋盘以及在内存中储存的形式: ![]()
源码
import torch
from util import *
import os
from GoDataset import GoDataset
from LetGoAI import LetGoAI
import matplotlib.pyplot as plt
# LetGo 参数
BATCH_SIZE = 64
WIDTH = 19
DATA_DIR = "./data/19"
MODEL_NAME = "PolicyModel2"
DEVICE = torch.device("cuda") # 训练硬件
seed = 666
torch.manual_seed(seed)
ai = LetGoAI(
width=WIDTH, lr=0.0002, device=DEVICE,
model_file=None
)
print("训练设备:", ai.device)
#==============================
# 开始训练
#==============================
total_loss = []
# 训练轮数设置
loop = int(input("输入断点轮数: "))
model_file_name = "./models/" + MODEL_NAME + "_{}.pt".format(loop)
if loop != 0:
if os.path.exists(model_file_name):
ai.policy_value_model = torch.load(model_file_name)
else:
print("未找到该断点!")
exit()
EPOCHS = int(input("输入要训练轮数: "))
showLoss = input("是否实时更新Loss:([yes],no)")
# Dataloader 实例化
files = os.listdir(DATA_DIR)
files = [DATA_DIR+"/"+name for name in files]
test_dataset = GoDataset(files, width=WIDTH)
dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE, shuffle=True)
print("数据加载成功,DataLoader参数如下:")
print("batch size =", BATCH_SIZE)
print("Data num =", len(dataloader.dataset))
# Loss 绘图设置
if showLoss!='no':
plt.ion()
figure, ax = plt.subplots()
else:
plt.xlabel("Step")
plt.ylabel("Loss")
plt.title("Training Loss")
for e in range(EPOCHS):
print('Epoch [{}/{}]: '.format(e+1, EPOCHS))
data_num = len(dataloader)
for batch_idx, (data, target) in enumerate(dataloader):
loss = ai.train(data, target)
if loss == 0: break
if batch_idx % 500 == 0:
print('Data [{}/{}] Loss = {}'.format(batch_idx, data_num, loss))
total_loss.append(loss)
# 更新图形
if showLoss != 'no':
ax.clear()
ax.plot(total_loss, label="Training Loss")
ax.set_xlabel('Batch Sample')
ax.set_ylabel("Loss")
ax.set_title("Training Loss")
ax.legend()
plt.pause(0.1)
if showLoss != 'no':
plt.ioff()
else:
plt.plot([x for x in range(len(total_loss))], total_loss)
plt.show()
print("完成{}轮训练!".format(EPOCHS))
ai.saveModel("./models/" + MODEL_NAME + "_{}.pt".format(loop + EPOCHS))
print("模型已经保存至 {}".format("./models/" + MODEL_NAME + "_{}.pt".format(loop + EPOCHS)))