
3 Transformer Language Model Architecture
语言模型应当:
- 接收一个 batch 的整数 token IDs 作为输入(即 shape 为
(batch_size, sequence_length)的torch.Tensor) - 返回一个(batch 化的)标准化的词汇分布(即 shape 为
(batch_size, sequence_length, vocab_size)的torch.Tensor),其中预测的分布对应于每个输入 token 的 next-word。
在训练语言模型时,我们利用这些 next-word 的预测结果来计算实际下一个单词与预测下一个单词之间的交叉熵损失(cross-entropy loss)。在推理过程中从语言模型中生成文本时,我们从最后一个时间步(即序列中的最后一项)获取预测的下一个单词分布,以生成序列中的下一个单词(例如,通过选取概率最大的 token、从分布中采样等),将生成的 token 添加到输入序列中,并重复此过程。
在本次作业的这一部分中,您将从零开始构建这个 Transformer 语言模型。我们将首先对模型进行一个高层次的描述,然后逐步详细阐述其各个组成部分。
3.1 Transformer LM
给定一系列的 token IDs,Transformer 语言模型会使用输入嵌入(input embedding)将 token IDs 转换为密集向量,将嵌入后的 token 通过 num_layers 个 Transformer 块进行处理,然后应用一个学习得到的线性投影(即 “output embedding” 或 “LM head”)来生成预测的下一个 token 的概率值。请参见 Figure 1 以获取示意图说明。
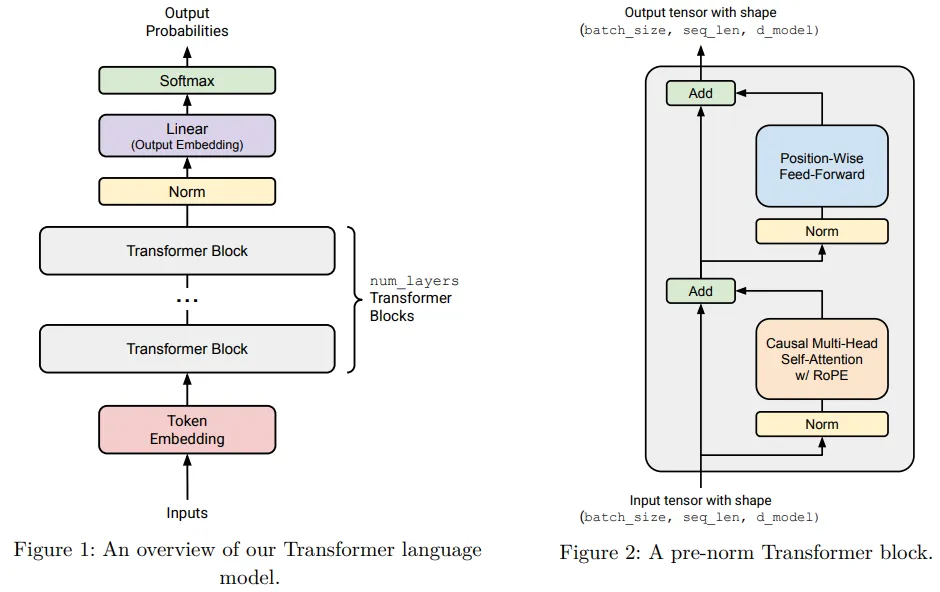
Token Embeddings
第一步中,Transformer 将(batch 化的)token IDs 序列嵌入为一系列包含 token 身份信息(token identity)的向量序列(Figure 1 中的红色块)。 更具体地说,给定一个 token IDs 序列,Transformer 语言模型使用一个 Token Embedding 层来生成一系列向量。每个 Embedding 层接收一个 shape 为 (batch_size, sequence_length) 的整数张量,并生成一个形状为 (batch_size, sequence_length, d_model) 的向量序列。
Pre-norm Transformer Block
在 embedding 之后,激活值由几个结构完全相同的神经网络层处理。
标准的仅解码器(decoder-only)型 Transformer 语言模型由 num_layers 个相同的层组成(通常称为 Transformer “blocks”)。每个 Transformer 块接收 shape 为 (batch_size, sequence_length, d_model) 的输入,并返回 shape 为 (batch_size, sequence_length, d_model) 的输出。
每个块都会在序列上聚合信息(通过自注意力)并对其进行非线性变换(通过前馈层)。经过 num_layers 个 Transformer 块之后,我们将取最终的激活值,并将其转换为词汇表上的分布。
我们将采用“预规范”型(Pre-norm)的 Transformer 块(详见第 3.4 节),此外,在最后一个 Transformer 块之后还需要使用层归一化(详情见下文),以确保其输出得到恰当的缩放。
经过这种规范处理后,我们将使用标准的学习型线性变换将 Transformer 块的输出转换为预测的下一个标记的对数概率。
3.2 Remark: Batching, Einsum and Efficient Computation
在整个 Transformer 模型中,我们将对许多 batch-like 的输入数据执行相同的计算操作。以下是几个示例:
- **Elements of a batch:**我们对每个 batch element 应用相同的 Transformer 前向操作。
- **序列长度:**像 RMSNorm 和前向传播这样的“位置相关”操作在序列的每个位置上都执行相同的操作。
- 注意力头:在“多头”注意力操作中,注意力操作是跨注意力头进行批处理的。
采用一种符合人体工程学的方式来进行此类操作是很有用的,这种方式能够充分利用 GPU,并且易于阅读和理解。许多 PyTorch 操作在开始时可以接收超出 “batch-like” 维度的额外维度,并能够高效地在这些维度上重复/广播操作。
例如,假设我们正在进行一个基于位置的、批次化的操作。我们有一个 shape 为 (batch_size, sequence_length, d_model) 的数据张量 ,我们希望对一个 shape 为 (d_model, d_model) 的矩阵 进行 batch 化的向量-矩阵乘法。在这种情况下, 将执行 batch 化的矩阵乘法,这是 PyTorch 中的一种高效的基本操作,其中 (batch_size, sequence_length) 这些维度是批量处理的。
因此,假设您的函数可能会接收到额外的 batch-like 维度,并将这些维度保留在 PyTorch shape 的开头是有帮助的。为了组织张量以便能够以这种方式进行 batch 处理,它们可能需要通过多次使用 view、reshape 和 transpose 来进行形状的调整。这可能有点麻烦,而且通常很难读懂代码在做什么以及张量的形状是什么。
一种更符合人体工程学的方案是在 torch.einsum 中使用 einsum notation,或者使用像 einops 或 einx 这样与框架无关的库。这两个关键的操作分别是 einsum(它可以对输入张量的任意维度进行张量收缩)和 rearrange(它可以对任意维度进行重新排序、连接和拆分)。事实证明,机器学习中的几乎所有操作都是维度变换和张量收缩的某种组合,偶尔还会包含(通常是点运算形式的)非线性函数。这意味着在使用 einsum notation 时,您的大部分代码会变得更加可读和灵活。 我们强烈建议该课程的学生学习并使用 einsum notation。之前没有接触过 einsum notation 的学生应该使用 einops,而已经熟悉 einops 的学生应该学习更通用的 einx。这两个包已经在我们提供的环境中安装好了。
这里我们给出了一些使用 einsum notation 的示例,这些是对 einops 文档的补充,您应该首先阅读该文档。
Example (einstein_example1): Batched matrix multiplication with einops.einsum
import torch
from einops import rearrange, einsum
## Basic implementation
Y = D @ A.T
# Hard to tell the input and output shapes and what they mean.
# What shapes can D and A have, and do any of these have unexpected behavior?
## Einsum is self-documenting and robust
# D A -> Y
Y = einsum(D, A, "batch sequence d_in, d_out d_in -> batch sequence d_out")
## Or, a batched version where D can have any leading dimensions but A is constrained.
Y = einsum(D, A, "... d_in, d_out d_in -> ... d_out")Example (einstein_example2): Broadcasted operations with einops.rearrange
# 我们有一批图像,对于每一张图像,我们希望根据某个缩放系数生成 10 个 dimmed 的版本:
images = torch.randn(64, 128, 128, 3) # (batch, height, width, channel)
dim_by = torch.linspace(start=0.0, end=1.0, steps=10)
## Reshape and multiply
dim_value = rearrange(dim_by, "dim_value -> 1 dim_value 1 1 1")
images_rearr = rearrange(images, "b height width channel -> b 1 height width channel")
dimmed_images = images_rearr * dim_value
## Or in one go:
dimmed_images = einsum(
images, dim_by,
"batch height width channel, dim_value -> batch dim_value height width channel"
)Example (einstein_example3): Pixel mixing with einops.rearrange
'''
假设我们有一组图像,以形状为(batch, height, width,channel)的张量形式表示,并且我们想要对图像的所有像素进行线性变换,但这种变换应该针对每个通道分别独立进行。我们的线性变换表示为一个形状为(height * width, height * width)的矩阵 𝐵
'''
channels_last = torch.randn(64, 32, 32, 3) # (batch, height, width, channel)
B = torch.randn(32*32, 32*32)
## Rearrange an image tensor for mixing across all pixels
channels_last_flat = channels_last.view(
-1, channels_last.size(1) * channels_last.size(2), channels_last.size(3)
)
channels_first_flat = channels_last_flat.transpose(1, 2)
channels_first_flat_transformed = channels_first_flat @ B.T
channels_last_flat_transformed = channels_first_flat_transformed.transpose(1, 2)
channels_last_transformed = channels_last_flat_transformed.view(*channels_last.shape)
# Instead, using einops:
height = width = 32
## Rearrange replaces clunky torch view + transpose
channels_first = rearrange(
channels_last,
"batch height width channel -> batch channel (height width)"
)
channels_first_transformed = einsum(
channels_first, B,
"batch channel pixel_in, pixel_out pixel_in -> batch channel pixel_out"
)
channels_last_transformed = rearrange(
channels_first_transformed,
"batch channel (height width) -> batch height width channel",
height=height, width=width
)
# Or, if you’re feeling crazy: all in one go using einx.dot (einx equivalent of einops.einsum)
height = width = 32
channels_last_transformed = einx.dot(
"batch row_in col_in channel, (row_out col_out) (row_in col_in)"
"-> batch row_out col_out channel",
channels_last, B,
col_in=width, col_out=width
)
'''
这里的第一种实现方式可以通过在前后添加注释来说明输入和输出的形状,这样会更清晰易懂,但这种方式显得较为笨拙,还容易出现错误。而使用 einsum 表示法,文档信息就包含在实现代码中了!
'''Einsum notation 能够处理任意的输入批处理维度,而且还有一个关键的优点,那就是它具有自解释性(self-documenting)。在使用 Einsum notation 编写的代码中,更清晰地能够看出输入和输出张量的相关形状。对于其余的张量,您可以考虑使用 Tensor 类型提示,例如使用 jaxtyping 库(并非专门针对 JAX)。
我们将在 assignment 2 中进一步讨论使用 einsum notation 时的性能影响,但目前要知道,它们几乎总是优于其他选择!
3.2.1 数学符号与内存顺序(Mathematical Notation and Memory Ordering)
许多机器学习论文在其表述中使用行向量,这使得所得到的表示形式与 NumPy 和 PyTorch 默认采用的“行优先”内存顺序相契合。使用行向量时,线性变换的形式看起来是
其中 ,行向量 .请注意,这使我们能够通过增加 的最外层维度来对输入进行批量处理,这意味着我们可以用向量输入 来替代矩阵输入.
在线性代数中,通常更常用的是使用列向量,此时线性变换的表现形式为
其中 ,列向量 .在这种情况下对输入进行分批处理时, 的 batch 维度应放在最后位置,因此 应替换为一个矩阵 .
在本次作业中,我们将主要使用列向量来进行数学符号表示,因为数学通常遵循这种表示方式。您需要记住,如果您想使用普通的矩阵乘法符号,那么您就必须像 Equation (1) 中的行向量惯例那样,将带有转置的矩阵进行相乘,因为 PyTorch 使用的是行优先的内存排列方式。如果您使用 einsum 进行线性代数运算,只要您正确标注轴,这通常就不会成为问题。顺便说一下,值得注意的是,像 Matlab、Julia 和 Fortran 这样的其他语言/线性代数包都使用列优先的内存排列方式,这意味着批处理维度在最后,但 Python 和相关包已经采用了 C 标准的行优先排列方式。
3.3 Basic Building Blocks: Linear and Embedding Modules
3.3.1 Parameter Initialization
高效地训练神经网络通常需要对模型参数进行精心的初始化——不恰当的初始化可能会导致诸如梯度消失或爆炸等不良现象。预规范变换器 (Pre-norm transformers) 对初始化的适应性异常强,但仍会对训练速度和收敛性产生显著影响。鉴于本次作业已经较长,我们将把具体细节留到 assignment 3 中讨论,而在此先为您提供一些大致的初始化值,这些值在大多数情况下应该都能很好地发挥作用。
目前,请使用:
Linear weights: truncated at .
Embedding: truncated at
RMSNorm:
您应当使用 torch.nn.init.trunc_normal_ 来初始化截断正态分布的权重。
3.3.2 Linear Module
线性层是 Transformer 模型以及一般神经网络中的一个基本构建模块。首先,您将实现自己的 Linear 类,该类继承自 torch.nn.Module 并执行线性变换:
请注意,我们未加入偏差项(bias),这与大多数现代语言模型的做法一致。
Problem (linear): Implementing the linear module
实现一个名为 Linear 的类,该类继承自 torch.nn.Module 并执行线性变换。您的实现应遵循 PyTorch 内置的 nn.Linear 模块的接口,但不包含偏置参数或相关参数。我们推荐以下接口:
def __init__(self, in_features, out_features, device=None, dtype=None):
'''
构建一个线性变换模块。此函数应接受以下参数:
in_features: int 输入数据的维度
out_features: int 输出数据的维度
device: torch.device | None = None 用于存储参数的 device
dtype: torch.dtype | None = None 参数的数据类型
'''
def forward(self, x: torch.Tensor) -> torch.Tensor:
'''对输入应用线性变换'''请务必:
- 继承(nn.Module)模块
- 调用超类构造函数
- 构建并存储您的参数为 (而非 ),将其放入一个 nn.Parameter 中
- 不要使用 nn.Linear 或 nn.functional.linear
对于初始化操作,使用上述设置以及 torch.nn.init.trunc_normal_ 来初始化权重。 要测试您的线性模块,请在 [adapters.run_linear] 处实现测试适配器。该适配器应将给定的权重加载到您的Linear 模块中,您可以使用 Module.load_state_dict 来实现此目的。然后,运行 uv run pytest -k test_linear 。
3.3.3 Embedding Module
如上所述,Transformer 的第一层是一个 embedding 层,它将整数 token IDs 转换为维度为 d_model 的向量空间。我们将实现一个自定义的 Embedding 类,该类继承自 torch.nn.Module(因此您不应使用 nn.Embedding)。forward 方法应通过使用一个 shape 为 (batch_size, sequence_length) 的 token IDs 的 torch.LongTensor(其中 token IDs 的值为整数)从一个 shape 为 (vocab_size, d_model) 的 embedding 矩阵中选取每个 token ID 的 embedding 向量。
Problem (embedding): Implement the embedding module
实现继承自 torch.nn.Module 的 Embedding 类,该类执行嵌入查找。您的实现应遵循 PyTorch 内置 nn.Embedding 模块的接口。我们建议使用以下接口:
def __init__(self, num_embeddings, embedding_dim, device=None, dtype=None):
'''
Construct an embedding module.
参数列表:
num_embeddings: int, vocabulary 大小
embedding_dim: int, embedding 向量维度
device: torch.device | None = None
dtype: torch.dtype | None = None
'''
pass
def forward(self, token_ids: torch.Tensor) -> torch.Tensor:
'''
查找给定 token ID 的 embedding 向量。
'''
pass请保证:
- 继承
nn.Module - 调用超类构造函数
- 把 embedding 矩阵初始化为一个
nn.Parameter - 将 embedding 矩阵的最后一个维度存为
d_model - 不要使用
nn.Embedding或者nn.functional.embedding
再次强调,使用上述配置进行初始化,并使用 torch.nn.init.trunc_normal_ 来初始化权重。
要测试你的实现,实现 [adapters.run_embedding] 的适配器,然后运行uv run pytest -k test_embedding
3.4 前归一化块(Pre-Norm Transformer Block)
每个 Transformer 块包含两个子层:
多头自注意力机制(multi-head self-attention mechanism)
位置相关的前馈网络(position-wise feed-forward network)
在最初的 Transformer 论文中,该模型在两个子层周围使用了残差连接,随后进行层归一化。这种架构通常被称为“后归一化(post-norm)” Transformer,因为层归一化是应用于子层输出的。
然而,大量研究发现,将层归一化从每个子层的输出移至每个子层的输入(在最后一个 Transformer 块后增加额外的层归一化)可以提高 Transformer 的训练稳定性——参见 Figure 2 中“前归一化(pre-norm)” Transformer 块的直观表示。
然后,每个 Transformer 块子层的输出通过残差连接与子层输入相加。前归一化的直观理解是,从输入嵌入到 Transformer 的最终输出之间存在一个干净的“残差流”,且未进行任何归一化,这据称可以改善梯度流动。这种前归一化 Transformer 现在是当今语言模型(如GPT-3、LLaMA、PaLM等)中使用的标准模型,因此我们将实现这一变体。我们将逐一介绍前归一化 Transformer 块的每个组件,并按顺序实现它们。
3.4.1 Root Mean Square Layer Normalization
A. Vaswani等人的原始 Transformer 实现使用了层归一化来对激活值进行归一化。遵循H. Touvron等人的做法,我们将使用**均方根层归一化(RMSNorm, 公式 4)**进行层归一化。
给定一个激活值的向量,RMSNorm 将按如下方式对每个激活值 进行重新缩放:
其中,,在这里,是一个可学习的“增益”参数(总共有 d_model 个这样的参数),而 𝜀 是一个超参数,通常固定为 1e-5。
你应该将输入类型向上转换到 torch.float32,以防止在对输入进行平方运算时发生溢出。总体来说,你的 forward 方法应该如下所示:
in_dtype = x.dtype
x = x.to(torch.float32)
# Your code here performing RMSNorm
...
result = ...
# Return the result in the original dtype
return result.to(in_dtype)Problem (rmsnorm): Root Mean Square Layer Normalization
将 RMSNorm 实现为 torch.nn.Module。我们推荐以下接口:
def __init__(self, d_model: int, eps: float = 1e-5, device=None, dtype=None):
'''
Construct the RMSNorm module.
接收参数:
d_model: int Hidden dimension of the model
eps: float = 1e-5 Epsilon value for numerical stability
device: torch.device | None = None Device to store the parameters on
dtype: torch.dtype | None = None Data type of the parameters
'''
pass
def forward(self, x: torch.Tensor) -> torch.Tensor:
'''
处理输入形状为 (batch_size, sequence_length, d_model) 的输入 x,并且返回一个相同形状的 Tensor
'''
pass如上所述,在进行归一化之前,请记住将输入上采样为 torch.float32 类型(之后再下采样回原始 dtype)。
为了测试你的实现,请在 [adapters.run_rmsnorm] 处实现测试适配器。然后,运行 uv run pytest -k test_rmsnorm
3.4.2 Position-Wise Feed-Forward Network(逐位置前馈网络)
在原始的 Transformer 论文中,Transformer 的前馈网络由两个线性变换组成,并且在两者之间有一个 ReLU 激活函数(ReLU() = max(0, ))。在最初的架构中,内部前馈层的维度通常是输入维度的 4 倍。
然而,与这种原始设计相比,现代语言模型通常会引入两个主要的变化:使用另一种激活函数,并采用一种门控机制。具体来说,我们将实现 “SwiGLU” 激活函数,该函数在像 Llama 3 和 Qwen 2.5 这样的大型语言模型中被采用,它将 SiLU(通常称为 Swish)激活函数与一种称为门控线性单元(GLU)的门控机制相结合。我们还将省略线性层中有时使用的偏置项,这与大多数现代大型语言模型 PaLM 和 LLaMA 的做法一致。
SiLU 激活函数的定义为:
如 Figure 3 所示,SiLU 激活函数与 ReLU 激活函数类似,但在零点处是平滑的。
门控线性单元(GLUs)最初由 Y. N. 戴芬等定义为通过一个经过 sigmoid 函数处理的线性变换和另一个线性变换得到的元素级乘积:
其中 表示 element-wise multiplicaton(逐元素乘法,也称 Hadamard 乘积)。门控线性单元被建议用于“通过为梯度提供一条线性路径来缓解深度架构中的梯度消失问题,同时保留非线性能力。”
将 SiLU(Swish) 和 GLU 结合在一起,我们就得到了 SwiGLU,我们将会把它用于我们的前馈网络:
其中,,,并且按照常规,. 对于具体的实现方式,将这个值四舍五入到接近 64 的倍数以提高硬件效率是可行的。
N. Shazeer 首先提出了将 SiLU/Swish 激活函数与 GLU 结合,并进行了实验,结果表明 SwiGLU 在语言建模任务中比诸如 ReLU 和 SiLU(不带门控)这样的基准模型表现更好。在本次作业的后续部分,你将对 SwiGLU 和 SiLU 进行比较。尽管我们已经提及了这些组件的一些启发式论点,但保持实证视角是很有好处的:Shazeer 论文中的一句著名引述是:
“We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.”
”对于这些架构为何如此有效,我们无法解释;如同其他一切事物,我们将它们的成功归因于神圣的眷顾。“
Problem(positionwise_feedforward): Implement the position-wise feed-forward network
实现由 SiLU 激活函数和 GLU 组成的 SwiGLU 前馈网络。
注意:在本特定情况下,您在实现过程中可以自由使用 torch.sigmoid 以确保数值稳定性。
在您的实现中,应将 设置为大约 ,同时要确保内部前馈层的维度是 64 的倍数,以便充分利用您的硬件。为了根据我们提供的测试对您的实现进行测试,您需要在 [adapters.run_swiglu] 处实现测试适配器。然后,运行 uv run pytest -k test_swiglu 来测试您的实现。
3.4.3 Relative Positional Embeddings(相对位置编码)
为了将位置信息注入模型中,我们将采用 “Rotary Position Embeddings” 方法,该方法常被称为 “RoPE”(旋转位置嵌入)。
对于位于第 个位置的 query token ,我们将应用一个成对旋转矩阵(pairwise rotation matrix) ,从而得到 。
在此,矩阵 会将一对对的 embedding 元素 旋转成一个 2d 向量,旋转角度为 ,其中 , 是常数。因此,我们可以认为矩阵 是一个大小为 的块对角矩阵,块 中有 ,并且具有以下形式:
因此,我们就得到了完整的旋转矩阵(pairwise rotation matrix)
其中 0 代表 2×2 的零矩阵。虽然可以构建完整的 矩阵,但一个好的解决方案应当利用该矩阵的特性来更高效地实现转换。由于我们只关心给定序列中 tokens 的相对旋转,因此我们可以重复使用 和 计算出的值,在不同 layer 和不同 batch 中都可以使用。如果您想要对其进行优化,可以使用由所有层引用的单个 RoPE 模块,并且它可以在初始化时通过 self.register_buffer(persistent=False) 创建一个 2d 预计算的正弦和余弦值缓冲区,而不是使用 nn.Parameter(因为我们不想去记忆这些固定的余弦和正弦值)。然后,我们对 执行完全相同的旋转过程,只是旋转角度为相应的 。需要注意的是,这一层没有可学习的参数。
Problem (rope): Implement RoPE
实现一个类 RotaryPositionalEmbedding ,该类会对输入的 Tensor 应用 RoPE 算法。
建议实现如下接口:
def __init__(self, theta: float, d_k: int, max_seq_len: int, device=None):
'''
构建RoPE模块, 并根据需要创建缓冲区
theta: float, RoPE 的 theta 值
d_k: int, query 向量和 key 向量的维度
max_seq_len: int, 输入的最大序列长度
device: torch.device | None = None Device to store the buffer on
'''
pass
def forward(self, x: torch.Tensor, token_positions: torch.Tensor) -> torch.Tensor:
'''
处理一个形状为 (..., seq_len, d_k) 的输入张量,并返回一个相同形状的张量。
请注意,你应该能够处理具有任意数量的批量维度的 x。
你应该假设 token 位置是一个形状为 (..., seq_len) 的 Tensor,用于指定 x 在序列维度上的 token 位置。
'''
pass您应当利用这些 token 位置来对您(可能已经预先计算好的)余弦和正弦张量按照序列维度进行切分。
为了测试您的实现,请完成 [adapters.run_rope] 并确保其能通过 uv run pytest -k test_rope 检查。
3.4.4 Scaled Dot-Product Attention(缩放点积注意力)
现在我们将按照 第 3.2.1 节 所述的方式实现缩放点积注意力机制。作为第一步,注意力操作的定义将使用 softmax 操作,这是一种将未归一化的分数向量转换为归一化分布的操作:
请注意,当输入值过大时, 可能会变为无穷大(此时,)。为避免这种情况,我们可以注意到 softmax 操作对所有输入值加上任何常数 都是不变的。我们可以利用这一特性来提高数值稳定性——通常,我们会从 的所有元素中减去 中的最大值,这样新的最大值就会变为 0。现在您将实现 softmax 函数,并使用此技巧来保证数值稳定性。
Problem (softmax): Implement softmax
编写一个函数,对一个 Tensor 应用 softmax 操作。
您的函数应接受两个参数:一个 Tensor 和一个维度 ,并对输入 Tensor 的第 个维度应用 softmax。输出 Tensor 应与输入 Tensor 具有相同的形状,但其第 个维度将变为一个标准化的概率分布。使用在第 个维度中减去该维度最大值的方法来避免数值稳定性问题。
为了测试您的实现,请完成 [adapters.run_softmax] 并确保它通过 uv run pytest -k test_softmax_matches_pytorch
现在我们可以用数学方式来定义注意力操作,具体表述如下:
其中 , ,
这里, 、、都是此操作的输入——请注意,这些并非可学习的参数。
**Masking:**有时对注意力操作的输出进行*掩码(mask)*处理会比较方便。掩码应具有形状 ,其中这个布尔矩阵的每一行 表示 query 应该关注哪些 key。
通常(并且有点令人困惑的是),位置 处的值为 True 表示 query 确实关注了 key ,而值为 False 则表示 query 不关注该 key。换句话说,“信息流”在 对中以值 True 的形式存在。例如,考虑一个 1×3 的掩码矩阵,其元素为 [[True, True, False]],这一个 query 向量仅关注前两个 key。
从计算角度来看,使用掩码要比对子序列进行注意力计算要高效得多,我们可以通过使用预 softmax 值 并在掩码矩阵中任何为 False 的位置添加 来实现这一点。
Problem (scaled_dot_product_attention): Implement scaled dot-product attention
实现缩放点积注意力函数。您的实现应能够处理形状为 (batch_size, …, seq_len, d_k) 的 keys 和 queries,以及形状为 (batch_size, …, seq_len, d_v) 的 values,其中 … 表示任何数量的其他类似 batch 的维度(如果有)。该实现应返回形状为 (batch_size, …, seq_len, d_v) 的输出。请参阅第 3.2 节以了解关于类似 batch 维度的讨论。
您的实现还应支持可选的用户提供的形状为 (seq_len, seq_len) 的布尔掩码。具有掩码值为 True 的位置的注意力概率应总计为 1,而具有掩码值为 False 的位置的注意力概率应为 0。
为了使用我们提供的测试用例对您的实现进行测试,请您在 [adapters.run_scaled_dot_product_attention] 中实现测试适配器。使用 uv run pytest -k test_scaled_dot_product_attention 可对三阶输入张量进行测试,而使用 uv run pytest -k test_4d_scaled_dot_product_attention 则可对四阶输入张量进行测试。
3.4.5 Causal Multi-Head Self-Attention
我们将按照 阿维斯瓦尼等人 论文第 3.2.2 节中的描述来实施多头自注意力机制。回想起来,从数学角度来看,应用多头注意力机制的操作定义如下:
其中,、、 分别是嵌入维度 、、 的第 个切片(其中 ,且每个切片的大小为 或 )。这里的 Attention 指的是在第 3.4.4 节中定义的缩放点积注意力操作。由此,我们可以构建多头自注意力操作:
在这里,可学习的参数为:、、 以及
由于在多头注意力操作中, 、、 是按多头进行分块的,因此我们可以认为 、、是沿着输出维度按每个头进行分离的。当这个机制正常运行,您应该通过三次矩阵乘法来计算 key、value 和 query 投影。
Causal masking(因果掩码)
您的实现应当确保模型不会关注序列中的后续 token。
换句话说,如果模型接收到一个 token 序列 ,并且我们想要计算前缀 (其中 )的下一个单词预测值,那么模型就不应该能够访问(关注)位置为 的 token。
因为在生成文本进行推理时模型无法获取这些 token(而且这些未来的 token 会泄露关于真正下一个单词身份的信息,从而简化了语言建模预训练目标)。对于输入 token 序列 ,我们可以简单地通过运行多头自注意力操作 次(针对序列中的 个唯一的前缀)来防止访问未来的 token。相反,我们将使用因果注意力掩码,它允许 token 关注序列中所有位置 。您可以使用 torch.triu 或广播式索引比较来构建这个掩码,并且您应该利用第 3.4.4 节中您已实现的缩放点积注意力实现已经支持注意力掩码。
Applying RoPE
RoPE 应当应用于 query 向量和 key 向量,但不应应用于 value 向量。此外,head 维度应被视为 batch 维度,因为在多头注意力中,对每个头的注意力计算是独立进行的。这意味着对于每个头,都应对 query 向量和 key 向量精确地应用相同的 RoPE 旋转。
Problem (multihead_self_attention): Implement causal multi-head self-attention
将 causal multi-head self-attention 实现为一个 torch.nn.Module ,你的实现应该至少接收以下参数:
- d_model: int, Transformer 块输入的维度。
- num_heads: int, 多头自注意力中使用的头的数量。
根据研究,设置参数
为了将您的实现与我们提供的测试进行对比,请在 [adapters.run_multihead_self_attention] 处实现测试适配器。然后运行以下命令来测试您的实现:uv run pytest -k test_multihead_self_attention
3.5 The Full Transformer LM
让我们开始组装 Transformer 块吧(回顾一下 Figure 2 会很有帮助)
Transformer 块包含两个“子层”,一个用于多头自注意力机制,另一个用于 SwiGLU 前馈网络。在每个子层中,我们首先执行 RMSNorm,然后进行主要操作(多头自注意力/前馈网络),最后添加残差连接。
具体来说,Transformer 块的前半部分(第一个“子层”)应执行以下一系列更新操作,以从输入 生成输出
Problem (transformer_block): Implement the Transformer block
按照第 3.4 节所述并参照 Figure 2 的描述来实现 pre-norm Transformer 块。
您的 Transformer 块应至少接受以下参数:
d_model:
int,表示 Transformer 块输入的维度num_heads:
int,表示多头自注意力中使用的头的数量d_ff:
int,表示位置感知前馈内层的维度。
为了测试您的实现,请实现适配器 [adapters.run_transformer_block] 。然后运行以下命令来测试您的实现:uv run pytest -k test_transformer_block
现在我们将这些模块组合在一起,按照 Figure 1 中的高级图示进行操作。按照第 3.1.0.1 节中对 Embedding 的描述,将此输入到 num_layers 个 Transformer 块中,然后将其传递到最终的层归一化和 LM head,从而得到一个关于词汇表的未归一化的分布(即预测值)
Problem (transformer_lm): Implementing the Transformer LM
是时候将所有内容整合起来了。按照第 3.1 节中的描述并参考 Figure 1 来实现 Transformer 语言模型。至少,你的实现应该能够接受上述关于 Transformer 块的所有构建参数,以及以下这些额外的参数:
- **vocab_size:**int,词库的大小,是确定词嵌入矩阵维度所必需的参数
- **context_length:**int,用于确定 RoPE 正弦和余弦缓冲区维度所需的最大上下文长度
- **num_layers:**int,要使用的 Transformer 块的数量
要根据我们提供的测试对您的实现进行测试,您首先需要在 [adapters.run_transformer_lm] 处实现测试适配器。然后,运行 uv run pytest -k test_transformer_lm 来测试您的实现。
Resource accounting
了解 Transformer 的各个组成部分是如何消耗计算资源和内存的是非常有用的。接下来我们将逐步进行一些基本的 “浮点运算次数统计”。在 Transformer 中,绝大多数的浮点运算都是矩阵乘法,因此我们的主要方法非常简单:
- 记录下整个 Transformer 前向传播过程中的所有矩阵乘法运算。
- 将每个矩阵乘法转换为所需的浮点运算次数。
在这前两步中,下面这句话将非常有用:
Rule:已知 ,,那么矩阵乘法运算 需要 次浮点运算。
要理解这一点,请注意 ,并且这种点积运算需要进行 次加法运算和 次乘法运算(共 次浮点运算)。然后,由于矩阵乘法 有 个元素,所以总的浮点运算次数为 。
现在,在您解决下一个问题之前,回顾一下您的 Transformer 块和 Transformer LM 的每个组成部分,并列出所有的矩阵乘法及其相关的浮点运算成本可能会有所帮助。
Problem (transformer_accounting): Transformer LM resource accounting
考虑使用我们的任务架构构建一个 GPT-2 超大型模型,其配置如下: **vocab_size:**50,257 **context_length:**1,024 **num_layers:**48 **d_model:**1,600 **num_heads:**25 **d_ff:**4,288(最接近的 64 的倍数,即 )
假设我们依据此配置构建了该模型。那么我们的模型会有多少可训练参数呢?假设每个参数都用单精度浮点数表示,那么仅仅加载这个模型就需要多少内存呢?
确定完成我们 GPT-2 XL 型模型的前向传播所需的矩阵乘法运算。这些矩阵乘法运算总共需要多少浮点运算次数?假设我们的输入序列包含
context_length个 token。根据您上述的分析,模型的哪些部分所需的浮点运算次数最多?
使用 GPT-2 小型版本(12 层,768 个 d_model,12 个头)、GPT-2 中型版本(24 层,1024 个 d_model,16 个头)和 GPT-2 大型版本(36 层,1280 个 d_model,20 个头)重复进行分析。随着模型规模的增大,Transformer 模型语言模型的哪些部分所占的总浮点运算次数(FLOPs)会相应增多或减少?
交付成果:针对每个模型,提供模型组件的分解及其相关的 FLOPs(作为前向传播所需总 FLOPs 的比例)。此外,提供一到两句话的描述,说明模型规模的变化如何改变每个组件的相对 FLOPs 比例。
以 GPT-2 XL 为例,将上下文长度增加至 16384。那么一次前向传播的总浮点运算次数会如何变化?模型各组成部分的浮点运算量的相对贡献又会怎样变化?
测试用例
Linear
uv run pytest -k test_linear
Embedding
uv run pytest -k test_embedding
RMSNorm
uv run pytest -k test_rmsnorm
Position-Wise FFN (SwiGLU)
uv run pytest -k test_swiglu
RoPE
uv run pytest -k test_rope
Softmax
uv run pytest -k test_softmax_matches_pytorch
Scaled dot product attention
uv run pytest -k test_scaled_dot_product_attention
uv run pytest -k test_4d_scaled_dot_product_attention
Causal Multi-Head Self-Attention
uv run pytest -k test_multihead_self_attention
Transformer block
uv run pytest -k test_transformer_block
Transformer LM
uv run pytest -k test_transformer_lm